ChatGPT 很智能,但是它有不足:知识库老旧,停留在2021年。另外对于企业,很多私有知识,并不希望全部暴露给GPT。因此结合ChatGPT的自然语言对话能力,加上私有知识库的数据,可以发挥更大价值。假如我们想利用OpenAI能力打造基于私有知识库的智能机器人,可以怎么做呢?
实现思路
当前主流解决方案是使用建立本地向量数据库,用户输入的时候先在本地向量数据库找出相似文本,然后再发给 LLM,让 LLM 帮我们整理答案。(更多内容感兴趣的查看结尾的问答)
大概步骤如下:
1、将知识库文档向量化(使用OpenAI中的embeddings)后存储到向量数据库(Chroma);
2、对于用户输入,在向量数据库中查询相关文档(如余弦相似算法)并按相似程度排序;
3、取最相关的前几个(如 top 5,需要考虑 token 数)作为背景知识,同用户请求一起发送给 LLM,让大模型根据背景知识整理并回答。
实现Demo
把 LangChain 的文档作为知识库,使用一个智能助手进行问答。
先直接看看实现效果
我们先问一下ChatGPT(gpt4):

再来问一下基于LangChain文档建立的问答机器人:(效果还是很明显的)
Q: LangChain是什么,能做什么
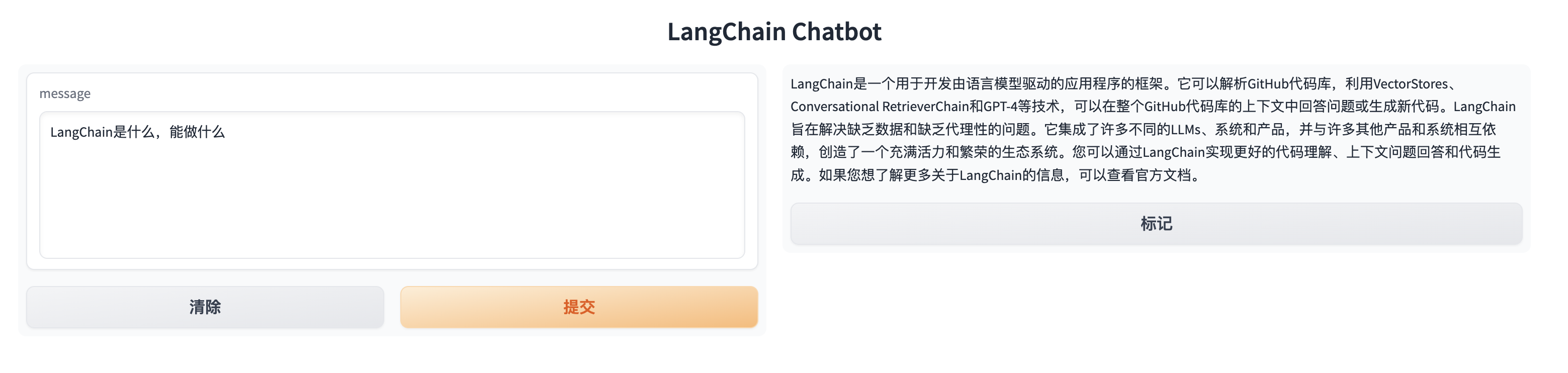
LangChain是一个用于开发由语言模型驱动的应用程序的框架。它可以解析GitHub代码库,利用VectorStores、Conversational RetrieverChain和GPT-4等技术,可以在整个GitHub代码库的上下文中回答问题或生成新代码。LangChain旨在解决缺乏数据和缺乏代理性的问题。它集成了许多不同的LLMs、系统和产品,并与许多其他产品和系统相互依赖,创造了一个充满活力和繁荣的生态系统。您可以通过LangChain实现更好的代码理解、上下文问题回答和代码生成。如果您想了解更多关于LangChain的信息,可以查看官方文档。
Q:怎么创建对话
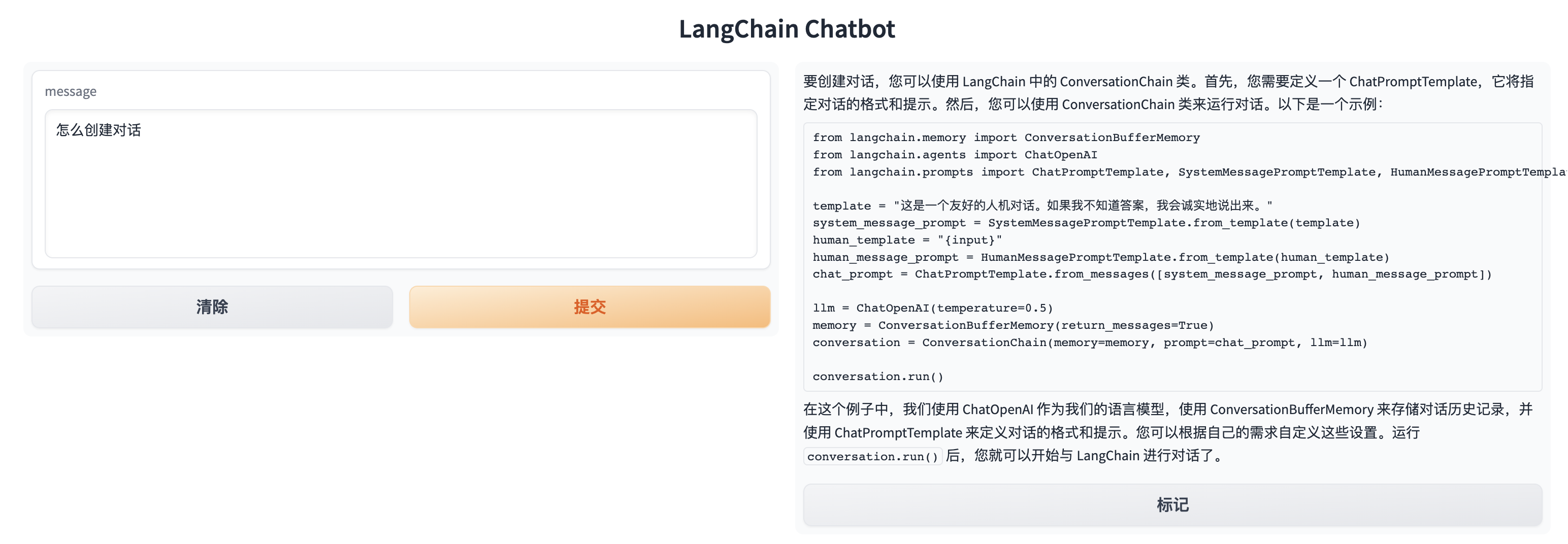
要创建对话,您可以使用 LangChain 中的 ConversationChain 类。首先,您需要定义一个 ChatPromptTemplate,它将指定对话的格式和提示。然后,您可以使用 ConversationChain 类来运行对话。以下是一个示例:
from langchain.memory import ConversationBufferMemory
from langchain.agents import ChatOpenAI
from langchain.prompts import ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate
template = "这是一个友好的人机对话。如果我不知道答案,我会诚实地说出来。"
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template = "{input}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
llm = ChatOpenAI(temperature=0.5)
memory = ConversationBufferMemory(return_messages=True)
conversation = ConversationChain(memory=memory, prompt=chat_prompt, llm=llm)
conversation.run()
在这个例子中,我们使用 ChatOpenAI 作为我们的语言模型,使用 ConversationBufferMemory 来存储对话历史记录,并使用 ChatPromptTemplate 来定义对话的格式和提示。您可以根据自己的需求自定义这些设置。运行 conversation.run() 后,您就可以开始与 LangChain 进行对话了。
具体实现
假设已有
OpenAI API KEY
可以访问OpenAI API的服务器
软件准备(python)
系统: Debain 11
安装 conda (python 版本管理器,类似 NodeJs 的 nvm)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
sh Miniconda3-latest-Linux-x86_64.sh
conda create -n langchain python=3.10 conda activate langchain
安装依赖
gradio
html2text
tiktoken
openai
chromadb
langchain
编码参考(python)
<pre>
<code type="python">
<span></span>
<span><span>import</span> os</span>
<span><span>import</span> gradio <span>as</span> gr</span>
<span></span>
<span><span>from</span> langchain<span>.</span>text_splitter <span>import</span> MarkdownTextSplitter</span>
<span><span>from</span> langchain<span>.</span>embeddings<span>.</span>openai <span>import</span> OpenAIEmbeddings</span>
<span><span>from</span> langchain<span>.</span>vectorstores <span>import</span> Chroma</span>
<span><span>from</span> langchain<span>.</span>chat_models <span>import</span> ChatOpenAI</span>
<span><span>from</span> langchain<span>.</span>chains <span>import</span> LLMChain</span>
<span><span>from</span> langchain<span>.</span>prompts <span>import</span> PromptTemplate</span>
<span></span>
<span></span>
<span>docs_dir <span>=</span> <span>"./docs"</span></span>
<span>index_dir <span>=</span> <span>"./indexes"</span></span>
<span>os<span>.</span>environ<span>[</span><span>"OPENAI_API_KEY"</span><span>]</span> <span>=</span> <span>input</span><span>(</span><span>"请输入 OpenAI API key:"</span><span>)</span></span>
<span>context_maxlength <span>=</span> <span>5000</span></span>
<span></span>
<span>docs_index <span>=</span> <span>None</span></span>
<span><span>def</span> <span>load_docs_index</span><span>(</span><span>)</span><span>:</span></span>
<span> <span>global</span> docs_index</span>
<span></span>
<span> <span>if</span> <span>None</span> <span>!=</span> docs_index<span>:</span></span>
<span> <span>return</span> docs_index</span>
<span></span>
<span> embeddings <span>=</span> OpenAIEmbeddings<span>(</span><span>)</span></span>
<span></span>
<span> </span>
<span> <span>if</span> <span>False</span> <span>==</span> os<span>.</span>path<span>.</span>isdir<span>(</span>index_dir<span>)</span><span>:</span></span>
<span> documents <span>=</span> generate_articles_documents<span>(</span>docs_dir<span>)</span></span>
<span> db <span>=</span> Chroma<span>.</span>from_documents<span>(</span>documents<span>,</span> embeddings<span>,</span> persist_directory <span>=</span> index_dir<span>)</span></span>
<span> db<span>.</span>persist<span>(</span><span>)</span></span>
<span> db <span>=</span> <span>None</span></span>
<span></span>
<span> </span>
<span> docs_index <span>=</span> Chroma<span>(</span>persist_directory <span>=</span> index_dir<span>,</span> embedding_function <span>=</span> embeddings<span>)</span></span>
<span></span>
<span> <span>return</span> docs_index </span>
<span></span>
<span></span>
<span><span>def</span> <span>generate_articles_documents</span><span>(</span>docs_dir<span>)</span><span>:</span></span>
<span> documents <span>=</span> <span>[</span><span>]</span></span>
<span> <span>for</span> article_file <span>in</span> os<span>.</span>listdir<span>(</span>docs_dir<span>)</span><span>:</span></span>
<span> path <span>=</span> os<span>.</span>path<span>.</span>join<span>(</span>docs_dir<span>,</span> article_file<span>)</span></span>
<span> </span>
<span> <span>if</span> os<span>.</span>path<span>.</span>isdir<span>(</span>path<span>)</span><span>:</span></span>
<span> documents <span>=</span> documents <span>+</span> generate_articles_documents<span>(</span>path<span>)</span></span>
<span></span>
<span> </span>
<span> <span>if</span> <span>not</span> os<span>.</span>path<span>.</span>isfile<span>(</span>path<span>)</span><span>:</span></span>
<span> <span>continue</span></span>
<span> <span>if</span> <span>(</span><span>not</span> path<span>.</span>endswith<span>(</span><span>".md"</span><span>)</span><span>)</span> <span>and</span> <span>(</span><span>not</span> path<span>.</span>endswith<span>(</span><span>".rst"</span><span>)</span><span>)</span><span>:</span></span>
<span> <span>continue</span></span>
<span></span>
<span> </span>
<span> tmpDocuments <span>=</span> article2documents<span>(</span>path<span>)</span></span>
<span> <span>if</span> tmpDocuments <span>==</span> <span>None</span><span>:</span></span>
<span> <span>continue</span></span>
<span> documents <span>=</span> documents <span>+</span> tmpDocuments</span>
<span> <span>print</span><span>(</span><span><span>f"parse file: </span><span><span>{</span>path<span>}</span></span><span> ... </span><span><span>{</span><span>len</span><span>(</span>tmpDocuments<span>)</span><span>}</span></span><span> documents"</span></span><span>)</span></span>
<span></span>
<span> <span>return</span> documents</span>
<span></span>
<span></span>
<span><span>def</span> <span>article2documents</span><span>(</span>path<span>)</span><span>:</span></span>
<span></span>
<span> <span>with</span> <span>open</span><span>(</span>path<span>,</span> <span>'r'</span><span>,</span> errors<span>=</span><span>"ignore"</span><span>)</span> <span>as</span> f<span>:</span></span>
<span> article <span>=</span> f<span>.</span>read<span>(</span><span>)</span></span>
<span> </span>
<span> </span>
<span> <span>if</span> <span>len</span><span>(</span>article<span>)</span> <span><</span> <span>10</span><span>:</span></span>
<span> <span>return</span> <span>None</span></span>
<span></span>
<span> </span>
<span> article_markdown <span>=</span> article</span>
<span></span>
<span> </span>
<span> markdown_splitter <span>=</span> MarkdownTextSplitter<span>(</span>chunk_size <span>=</span> <span>512</span><span>,</span> chunk_overlap <span>=</span> <span>32</span><span>)</span></span>
<span> documents <span>=</span> markdown_splitter<span>.</span>create_documents<span>(</span><span>[</span>article_markdown<span>]</span><span>)</span></span>
<span></span>
<span> </span>
<span> <span>for</span> doc <span>in</span> documents<span>:</span></span>
<span> doc<span>.</span>metadata <span>=</span> <span>dict</span><span>(</span>path <span>=</span> path<span>)</span></span>
<span></span>
<span> <span>return</span> documents</span>
<span></span>
<span></span>
<span><span>def</span> <span>get_prompt_chat</span><span>(</span><span>)</span><span>:</span></span>
<span> template <span>=</span> <span>(</span><span>"你作为一个AI小助手,请根据上下文内容,回复用户关于 langchain (一个 python 工具库) 使用上的问题。"</span></span>
<span> <span>"请尽可能给出详细,清晰地友好指导。"</span></span>
<span> <span>"上下文内容是 markdown 格式,所以你的回复也使用 markdown 格式,这样可以更加方便的表示 链接,代码块 等内容。 "</span></span>
<span> <span>"如果你不知道答案,或者用户的提问与 langchain 无关,请回复“不知道”即可。\n\n"</span></span>
<span> <span>"### 上下文(开始) ###\n"</span></span>
<span> <span>"{context}\n"</span></span>
<span> <span>"### 上下文(结束) ###\n\n"</span></span>
<span> <span>"### 用户提问(开始) ###\n"</span></span>
<span> <span>"{human_input}\n"</span></span>
<span> <span>"### 用户提问(结束) ###\n\n"</span></span>
<span> <span>"AI: "</span><span>)</span></span>
<span> prompt <span>=</span> PromptTemplate<span>(</span></span>
<span> input_variables<span>=</span><span>[</span><span>"context"</span><span>,</span> <span>"human_input"</span><span>]</span><span>,</span></span>
<span> template<span>=</span>template</span>
<span> <span>)</span></span>
<span> <span>return</span> prompt</span>
<span></span>
<span><span>def</span> <span>get_prompt_optimize</span><span>(</span><span>)</span><span>:</span></span>
<span> template <span>=</span> <span>(</span><span>"请你扮演一个文档小助手,协助用户更好的跟智能文档进行提问。 "</span></span>
<span> <span>"请把用户的输入,去除情绪和无意义的表达,将有用信息翻译为英文,以便尽可能地贴近匹配文档内容。\n"</span></span>
<span> <span>"下面是用户的输入:\n"</span></span>
<span> <span>"{human_input}"</span><span>)</span></span>
<span> prompt <span>=</span> PromptTemplate<span>(</span></span>
<span> input_variables<span>=</span><span>[</span><span>"human_input"</span><span>]</span><span>,</span></span>
<span> template<span>=</span>template</span>
<span> <span>)</span></span>
<span> <span>return</span> prompt</span>
<span></span>
<span></span>
<span>llm <span>=</span> <span>None</span></span>
<span><span>def</span> <span>get_llm</span><span>(</span><span>)</span><span>:</span></span>
<span> <span>global</span> llm</span>
<span> <span>if</span> <span>None</span> <span>!=</span> llm<span>:</span></span>
<span> <span>return</span> llm</span>
<span></span>
<span> llm <span>=</span> ChatOpenAI<span>(</span></span>
<span> temperature <span>=</span> <span>0.1</span><span>,</span></span>
<span> model_name <span>=</span> <span>"gpt-3.5-turbo"</span><span>,</span></span>
<span> request_timeout <span>=</span> <span>90</span></span>
<span> <span>)</span></span>
<span> <span>return</span> llm</span>
<span></span>
<span></span>
<span><span>def</span> <span>optimize_user_message</span><span>(</span>message<span>)</span><span>:</span></span>
<span></span>
<span> llm <span>=</span> get_llm<span>(</span><span>)</span></span>
<span> prompt <span>=</span> get_prompt_optimize<span>(</span><span>)</span></span>
<span> chain <span>=</span> LLMChain<span>(</span>llm <span>=</span> llm<span>,</span> prompt <span>=</span> prompt<span>,</span> verbose <span>=</span> <span>True</span><span>)</span></span>
<span></span>
<span> </span>
<span> newMessage <span>=</span> chain<span>.</span>run<span>(</span><span>{</span><span>"human_input"</span><span>:</span> message<span>}</span><span>)</span></span>
<span> <span>print</span><span>(</span><span><span>f"##\nnewMessage:\n</span><span><span>{</span>newMessage<span>}</span></span><span>\n##\n"</span></span><span>)</span></span>
<span> <span>return</span> newMessage</span>
<span></span>
<span></span>
<span><span>def</span> <span>get_message_context</span><span>(</span>message<span>)</span><span>:</span></span>
<span></span>
<span> </span>
<span> message <span>=</span> optimize_user_message<span>(</span>message<span>)</span></span>
<span></span>
<span> </span>
<span> index <span>=</span> load_docs_index<span>(</span><span>)</span></span>
<span> docs <span>=</span> index<span>.</span>similarity_search<span>(</span>message<span>,</span> <span>30</span><span>)</span></span>
<span> context <span>=</span> <span>""</span></span>
<span> duplicatedCheckDict <span>=</span> <span>dict</span><span>(</span><span>)</span></span>
<span> <span>for</span> doc <span>in</span> docs<span>:</span></span>
<span> content <span>=</span> doc<span>.</span>page_content</span>
<span> <span>if</span> duplicatedCheckDict<span>.</span>get<span>(</span>content<span>,</span> <span>None</span><span>)</span> <span>!=</span> <span>None</span><span>:</span></span>
<span> <span>continue</span></span>
<span> duplicatedCheckDict<span>[</span>content<span>]</span> <span>=</span> <span>True</span></span>
<span> context <span>=</span> context <span>+</span> doc<span>.</span>page_content <span>+</span> <span>"\n"</span></span>
<span> </span>
<span> <span>if</span> <span>len</span><span>(</span>context<span>)</span> <span></span> context_maxlength<span>:</span></span>
<span> <span>break</span></span>
<span> </span>
<span> <span>return</span> context</span>
<span></span>
<span></span>
<span><span>def</span> <span>article_chat</span><span>(</span>message<span>)</span><span>:</span></span>
<span></span>
<span> context <span>=</span> get_message_context<span>(</span>message<span>)</span></span>
<span></span>
<span> </span>
<span> llm <span>=</span> get_llm<span>(</span><span>)</span></span>
<span> prompt <span>=</span> get_prompt_chat<span>(</span><span>)</span></span>
<span> chain <span>=</span> LLMChain<span>(</span>llm <span>=</span> llm<span>,</span> prompt <span>=</span> prompt<span>,</span> verbose <span>=</span> <span>True</span><span>)</span></span>
<span></span>
<span> </span>
<span> response <span>=</span> chain<span>.</span>run<span>(</span><span>{</span><span>"context"</span><span>:</span> context<span>,</span> <span>"human_input"</span><span>:</span> message<span>}</span><span>)</span></span>
<span> <span>return</span> response</span>
<span></span>
<span><span>if</span> __name__ <span>==</span> <span>'__main__'</span><span>:</span></span>
<span></span>
<span> </span>
<span> load_docs_index<span>(</span><span>)</span></span>
<span></span>
<span> </span>
<span> webapp <span>=</span> gr<span>.</span>Interface<span>(</span>fn <span>=</span> article_chat<span>,</span></span>
<span> inputs <span>=</span> gr<span>.</span>Textbox<span>(</span>lines <span>=</span> <span>6</span><span>,</span> placeholder <span>=</span> <span>"请输入您关于langchain文档的问题"</span><span>)</span><span>,</span></span>
<span> </span>
<span> outputs <span>=</span> gr<span>.</span>Markdown<span>(</span><span>"The response will be shown here."</span><span>)</span><span>,</span></span>
<span> title <span>=</span> <span>"LangChain Chatbot"</span><span>)</span></span>
<span> webapp<span>.</span>launch<span>(</span>inbrowser<span>=</span><span>True</span><span>,</span> share <span>=</span> <span>False</span><span>,</span> server_name <span>=</span> <span>"0.0.0.0"</span><span>,</span> server_port <span>=</span> <span>8080</span><span>)</span></span>
<span></span>
</code>使用文档
把 langchain 的文档作为知识库,使用一个智能助手进行问答。
安装依赖: pip install -r requirements.txt
下载 langchain 代码库中的 docs 目录( https://github.com/hwchase17/langchain/tree/master/docs ),放在当前目录下
运行 docs-chat.py ,打开浏览器进行问答体验
问一下 ChatGPT 有什么好的实践方案
Q : LLM 大模型结合本地私有知识库建立智能问答机器人,有什么好的实践方案?
ChatGPT:
要将LLM(Large Language Model,大型语言模型)与本地私有知识库结合,以建立智能问答机器人,可以遵循以下实践方案:
数据预处理:首先,整理和清洗您的本地私有知识库,确保数据质量。将数据转换为结构化或半结构化的格式,如JSON、CSV或XML,以便于处理。
知识库扩展:将您的私有知识库与其他可用的公共知识库(如维基百科、DBpedia等)结合,以提高问答机器人的知识覆盖范围。
模型选择:选择一个适合您需求的预训练大型语言模型,如OpenAI的GPT系列模型(GPT-2、GPT-3或GPT-4)或其他类似模型。
模型微调:使用您的知识库数据对预训练模型进行微调。这可以通过构建一个包含问题-答案对的数据集来实现。微调过程将使模型更好地适应您的私有知识库,从而提高问答性能。
API构建:为您的智能问答机器人构建一个API,以便于与其他应用程序或服务进行集成。API应该接受用户问题作为输入,并返回模型生成的答案。
用户界面:设计一个用户友好的界面,让用户能够轻松地与您的问答机器人互动。这可以是一个网页、移动应用或者聊天界面。
性能监测与优化:持续监测问答机器人的性能,收集用户反馈,并根据反馈对模型和知识库进行优化。这可能包括添加新的知识、修复错误答案或进一步微调模型。
遵循道德与法律规定:确保您的智能问答机器人遵循相关的道德和法律规定,尊重用户隐私,并确保生成的内容不含有不当或有害信息。
通过遵循这些实践方案,您可以建立一个结合本地私有知识库的智能问答机器人,为用户提供高质量的问答服务。
Q: 没错。但微调大模型成本很高,而且文档更新频率较高,不可能做到每次变更后都重新微调。有没有更简单易行的方案。可以聚焦在智能信息检 索这个应用场景。
ChatGPT:
当然,理解到微调大型语言模型的挑战和成本,可以考虑以下的方案来实现大模型与本地私有知识库的结合,聚焦在智能信息检索这个应用场景。 LLM作为查询解释器:首先,LLM可以作为查询的解释器,帮助用户更准确地表述他们的问题或需求。用户可能不总是清楚如何最有效地表述查询,特别是在寻找复杂
的技术文档或专业知识时。LLM可以帮助解析这些复杂的查询,并将它们转化为更结构化的查询,以便能够在知识库中找到正确的文档。 利用现有的信息检索工具:对于私有知识库的管理,可以使用成熟的信息检索工具(例如Elasticsearch或Solr)。这些工具可以索引大量文档,并能快速返回查
询的结果。重点是,这些工具可以处理结构化查询,并在必要时进行相关性评分或排序。 模型与检索工具的结合:用户将问题提交给LLM,LLM生成结构化查询,然后将这个查询发送给信息检索工具。信息检索工具在知识库中查找相关文档并返回结果。然
后,LLM可以帮助解析这些结果,并将其呈现给用户。 持续学习和改进:随着用户的使用,可以收集用户的反馈来改进系统。例如,如果用户对某个查询的结果不满意,他们可以提供反馈,然后使用这些反馈来改进LLM的
查询生成或信息检索工具的排序算法。
这种方法的优点是可以利用现有的工具和资源,避免了微调大型模型的需要,并且可以适应文档的更新。这个方案只需要对LLM进行一定的训练,使其能够解析用户的 查询和信息检索工具的结果,而不需要对具体的文档内容有深入的理解。
Q:不错。现在有一种方案是:1 将知识库文档向量化后存储到向量数据库。2 对于用户输入,在向量数据库中查询相关文档(如余弦相似算法)并按相似程度排序。3 取最相关的前几个(如 top 5,需要考虑 token 数)作为背景知识,同用户请求一起发送给 LLM,让大模型根据背景知识整理并回答。请问这种方案是否可行,有哪些可优化的地方?
ChatGPT:
你提到的方案是非常可行的,并且已经在一些系统中得到了应用。这种方案有效地结合了向量化的信息检索和大型语言模型的理解能力,可以在大型的知识库中提供精
确且深入的回答。以下是对这种方案的一些优化建议:
向量化优化:使用更先进的技术进行文档向量化可能会提高结果的质量。例如,使用Transformer等深度学习模型进行文档的向量化可能比简单的TF-IDF或者词袋 模型更能捕捉到文档的语义内容。
查询扩展和修订:在向量数据库中查询时,可以使用一些查询扩展或查询修订的策略来提高结果的相关性。例如,可以使用同义词,近义词或相关词来扩展查询,或者
使用用户反馈来修订查询。
结果融合和排名:在从向量数据库中检索结果后,可能需要一种方法来融合和排名这些结果。这可能包括计算每个结果的置信度得分,然后根据这些得分进行排序。可
以使用一些学习排名的方法来优化这个过程。
使用上下文信息:在构建用户请求和背景知识的输入时,可以考虑使用更多的上下文信息。例如,如果用户在一个会话中提出了多个问题,那么之前的问题和回答可能
会对理解当前的问题有帮助。
反馈和持续学习:可以收集用户的反馈,并使用这些反馈来持续改进系统。例如,如果用户对某个回答不满意,他们可以提供反馈,然后可以使用这些反馈来优化向量
化,查询,排名等步骤。
最后,对于这种方案的成功,保持数据的质量和更新至关重要。需要确保知识库的内容是准确和最新的,并定期进行向量化和索引的更新。
Q: 文本向量化并进行近似查询的方法,相比传统的文本检索,如 elastic search,有哪些优缺点?
ChatGPT:
文本向量化并进行近似查询的方法主要是将文本转化为向量形式,并在向量空间中进行近似查询。这样的方式常常通过深度学习的方法,如Word2Vec,GloVe,FastText或者BERT等进行。 优点包括:
语义理解:向量化方法通常能够捕获到文本中的语义信息,即使在词汇层面上看似不相关的查询和文档也能匹配。例如,一个查询是“狗”而文档中的词是“犬”,虽然 两者在词汇上不同,但语义相近,向量化方法可以识别出这种关联。
模糊匹配:向量化方法可以支持模糊匹配,这对于处理拼写错误或是用词不准确的查询非常有帮助。
无需预定义的词汇表:向量化方法通常不需要预定义的词汇表,能够处理开放词汇表的问题,这对于处理网上的用户生成内容或其他非标准文本特别有用。
然而,缺点也很明显:
计算成本:向量化方法通常需要更多的计算资源和存储空间。虽然有近似最近邻搜索的方法来降低计算成本,但这仍然需要大量的计算资源和存储空间。
缺乏解释性:向量化方法的结果通常缺乏解释性,很难解释为什么一个特定的文档和查询匹配。
实时更新的挑战:对于需要实时更新的索引,向量化方法可能比传统的文本检索方法更难处理。向量化方法通常需要重新训练和重新索引,这可能在处理大量的实时更
新时变得不可行。
相比之下,传统的文本检索方法,如Elasticsearch,基于词汇的匹配和倒排索引来实现快速的文本检索。 优点包括:
高效率:倒排索引能够非常快速地返回结果,适合大规模的文档集合。 解释性强:传统的文本检索方法的结果具有很强的解释性 用户可以明白为什么某个文档被匹配到
Q: 介绍一下openAI中的embeddings
OpenAI中的embeddings通常指的是将文本或其他类型的数据转换为固定长度的向量表示,以便在机器学习和深度学习模型中使用。这些向量表示能够捕捉数据中的语义信息和关系,从而有助于提高模型的性能。
在自然语言处理(NLP)领域,词嵌入(word embeddings)和句子嵌入(sentence embeddings)是最常见的embedding类型。词嵌入将单词转换为向量,而句子嵌入将整个句子转换为向量。这些嵌入可以通过预训练的模型(如Word2Vec、GloVe、BERT等)生成,也可以在特定任务中训练得到。
OpenAI是一种用于定义和描述API接口的规范,它可以帮助开发者轻松地构建和集成各种服务。在NLP应用中,开发者可以利用OpenAI规范来调用预训练的embedding模型,将文本数据转换为向量表示,从而简化模型开发和部署过程。
总之,OpenAI中的embeddings是一种将数据转换为向量表示的技术,它在自然语言处理和其他领域具有广泛的应用。通过使用OpenAI规范,开发者可以更轻松地集成和使用这些embedding模型,从而提高应用的性能和效率。
Q:介绍一下向量数据库Chroma
向量数据库Chroma是一个高性能、可扩展的向量搜索引擎,用于存储和检索大量高维向量数据。Chroma的主要应用场景是相似性搜索,即在大规模数据集中找到与给定向量最相似的向量。这在许多领域都有广泛应用,如推荐系统、计算机视觉、自然语言处理等。
Chroma的主要特点包括:
高性能:Chroma使用高效的索引结构和搜索算法,如近似最近邻(ANN)搜索,以实现快速的向量检索。这使得它能够在大规模数据集上提供实时的搜索性能。
可扩展性:Chroma支持分布式部署和水平扩展,可以轻松地处理大量向量数据。通过添加更多的计算资源,Chroma可以实现线性扩展,以满足不断增长的数据需求。
灵活性:Chroma提供了丰富的API和接口,使得开发者可以轻松地将其集成到各种应用和系统中。此外,Chroma支持多种数据类型和距离度量,以满足不同场景的需求。
容错性和高可用性:Chroma具有数据冗余和故障恢复功能,可以确保数据的安全和可靠。同时,通过负载均衡和自动故障转移等技术,Chroma可以实现高可用性,以支持关键业务场景。
总之,向量数据库Chroma是一个高性能、可扩展的向量搜索引擎,适用于大规模相似性搜索任务。通过使用Chroma,开发者可以轻松地构建和部署基于向量数据的应用和服务。
